- WHAT WE DO
Additional Services


- Industries

Case Study: Multilingual Retail Marketing
New AI Content Creation Solutions for a Sports and Apparel Giant
- RESOURCES

- WHO WE ARE

What We Do Home
Generative AI
- AI Translation Services
- Content Remix
AI Training
- Aurora AI Studio™
Machine Translation
- MT Tracker
Instant Interpreter
Smart Onboarding
Translation Service Models
Content Services
- Technical Writing
- Training & eLearning
- Financial Reports
- Digital Marketing
- SEO & Content Optimization
Translation Services
- Video Localization
- Software Localization
- Website Localization
- Translation for Regulated Companies
- Interpretation
- Instant Interpreter
- Live Events
- Language Quality Services
Testing Services
- Functional QA & Testing
- Compatibility Testing
- Interoperability Testing
- Performance Testing
- Accessibility Testing
- UX/CX Testing
Industries Home
Life Sciences Translations
- Pharmaceutical Translations
- Clinical Trial Translations
- Regulatory Translations
- Post-Approval Translations
- Corporate Pharma Translations
- Medical Device Language Services
- Validation and Clinical
- Regulatory Translations
- Post-Authorization Translations
- Corporate Medical Device Translations
Banking & Finance
Retail
Luxury
E-Commerce
Games
Automotive
Consumer Packaged Goods
Technology
Industrial Manufacturing
Legal Services
Travel & Hospitality
Insights
- Blog Posts
- Case Studies
- Whitepapers
- Solution Briefs
- Infographics
- eBooks
- Videos
Webinars
Lionbridge Knowledge Hubs
- Positive Patient Outcomes
- Modern Clinical Trial Solutions
- Patient Engagement
- AI Thought Leadership
![]()
SELECT LANGUAGE:

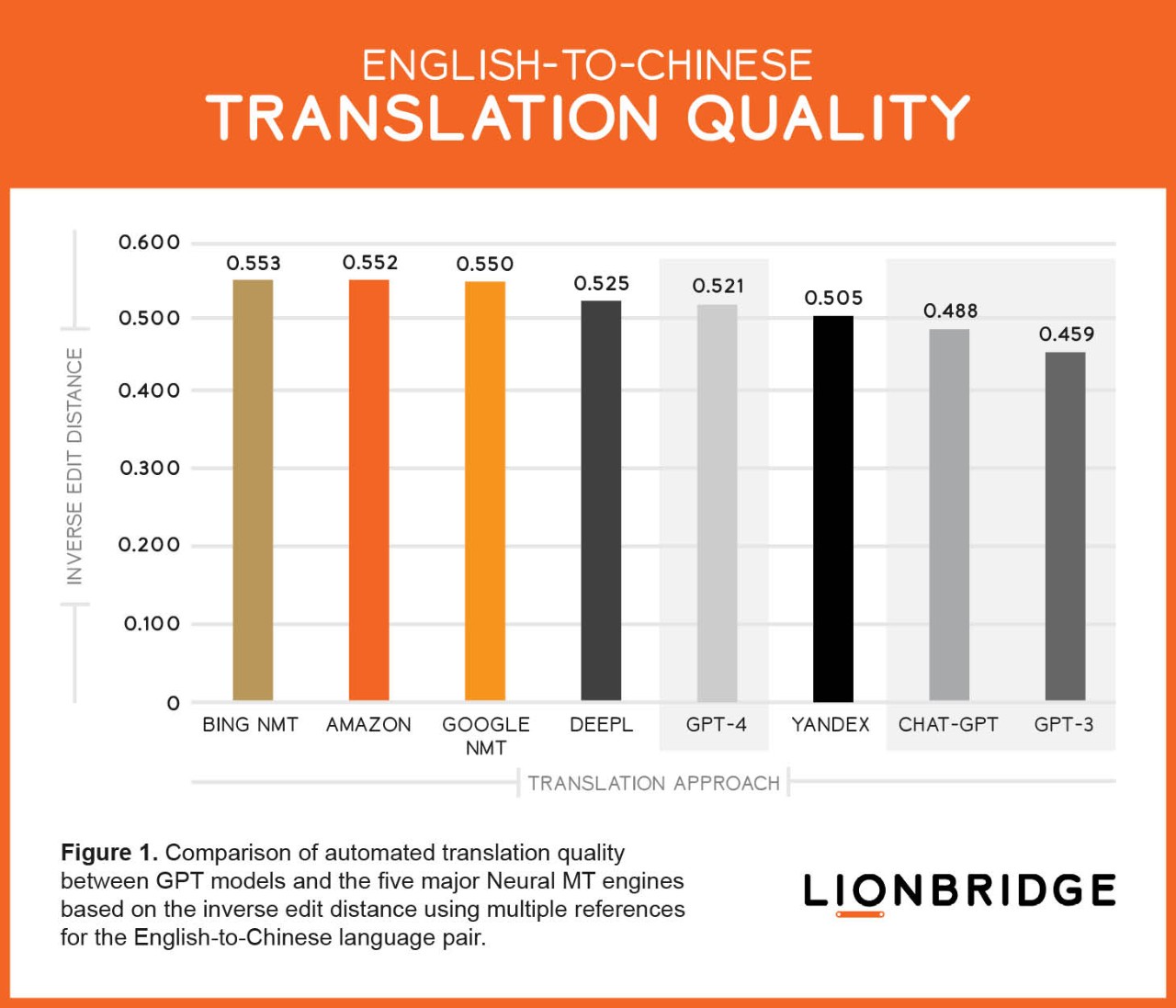
For the first time in our Machine Translation (MT) comparative evaluations, a generative Artificial Intelligence (AI) model provided better translation output than a Neural Machine Translation (NMT) engine. Specifically, Large Language Model (LLM) GPT-4 slightly outperformed Yandex for the English-to-Chinese language pair.
It is worthwhile to examine the implications of this development.
If it is a sign that the Neural Machine Translation paradigm is coming to an end or dramatically changing, we can expect a transformation in Machine Translation delivery that will include a leap in translation quality, greater adoption, and an ability to push out more content.
MT providers must be at the forefront of the technology change and consider how it will impact their current MT engine to provide an offering that fully capitalizes on advancements. MT buyers must stay on top of developments to make wise investments, which will likely include some LLM-based technology instead of pure Neural MT offerings.
LLM Surpasses Neural MT Engine Output: Is it Significant?
While the result of this evaluation is a breakthrough, let’s put it into perspective. It encompassed just one model for just one language pair. The LLM performed better than only one NMT engine out of five and in just one type of MT evaluation, a multireference evaluation. Is this achievement still a big deal? You bet it is.
While the finding may seem insignificant when put in the above context, it is noteworthy because it’s the first time a different type of MT approach has beaten a Neural MT engine since the advent of NMT. Moreover, a “non-MT” approach — a multi-purpose language automation not specifically prepared for Machine Translation — has beaten the NMT engine. This last detail makes it remarkable for the GPT-4 Large Language Model to surpass an NMT engine.
What Does ChatGPT-4’s Notable Translation Result Mean for the Neural Machine Translation Paradigm?
Since February 2022, we have publicly questioned the possibility of an MT paradigm shift in the not-so-distant future. See our Machine Translation tracker commentary for more about our thinking on this topic during this time. These latest comparative results provide additional proof that some significant change is forthcoming.
But don’t jump to conclusions so fast. It’s still too early to say that Large Language Models (LLMs) will replace NMT engines, let alone that the change is imminent. We need more time to evaluate much more data. There are too many factors to consider, and LLM technology must significantly improve to be a viable translation solution for enterprises.
It’s likely for a paradigm change to start with NMT engines adopting some LLM approaches as NMT and LLM technologies share many commonalities.

How Does NMT and LLM Translation Output Compare for Three Language Pairs?
Let’s compare the translation results between the five top Neural Machine Translation engines and some GPT models for three language pairs.
We calculated the quality level based on the inverse edit distance using multiple references for the following language pairs: English-to-Chinese (EN-ZH), English-to-Spanish (EN-ES), and English-to-German (EN-DE).
The edit distance measures the number of edits a human must make to the MT output for the resulting translation to be as good as a human translation. For our calculation, we compared the raw MT output against 10 different human translations — multiple references — instead of just one human translation. The inverse edit distance means the higher the resulting number, the better the quality.
Figure 1 shows little difference in the reverse Edit Distance among the NMT engines and LLMs, which means they performed similarly. However, notably Large Language Model GPT-4 produced slightly better translation quality than Yandex NMT for the English-to-Chinese language pair.
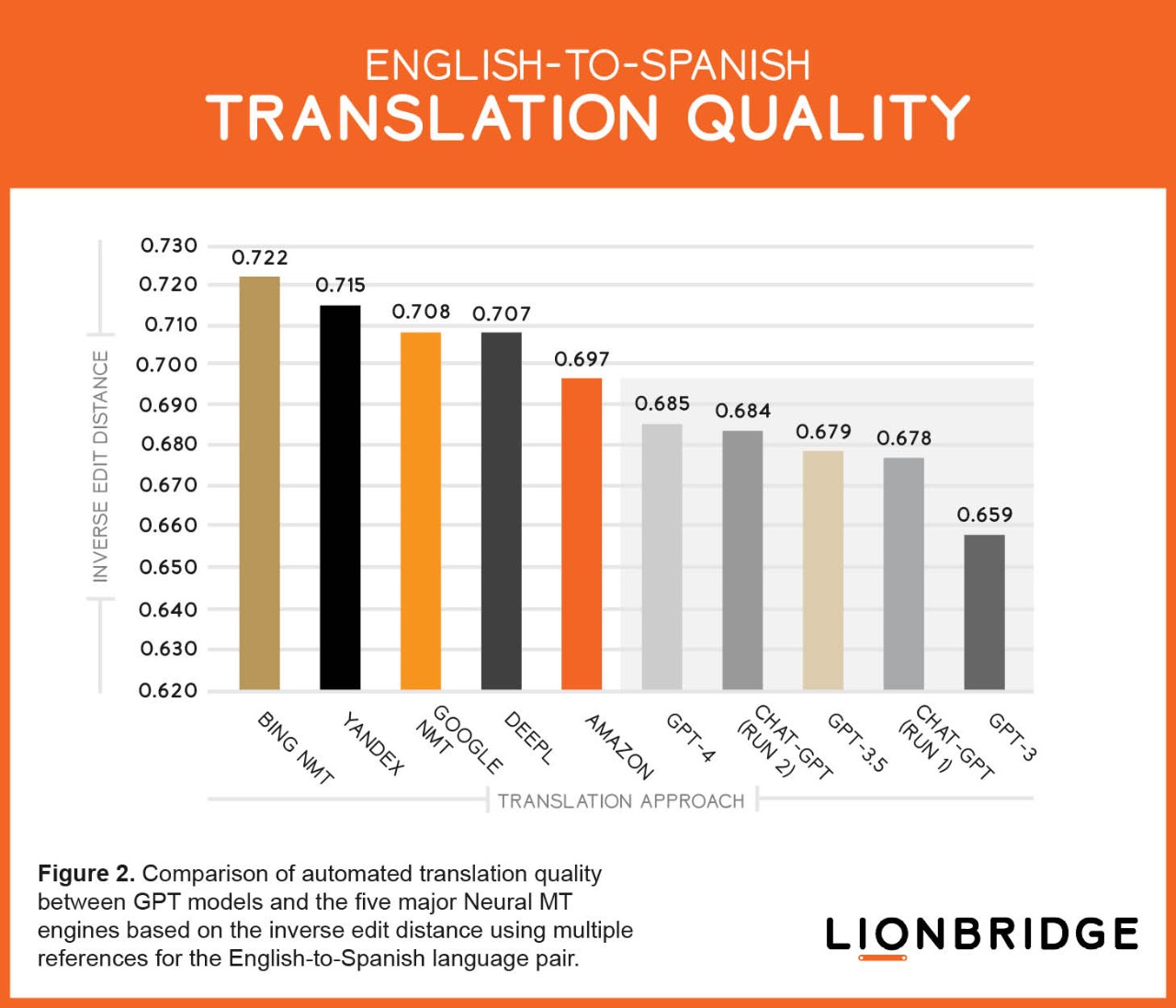
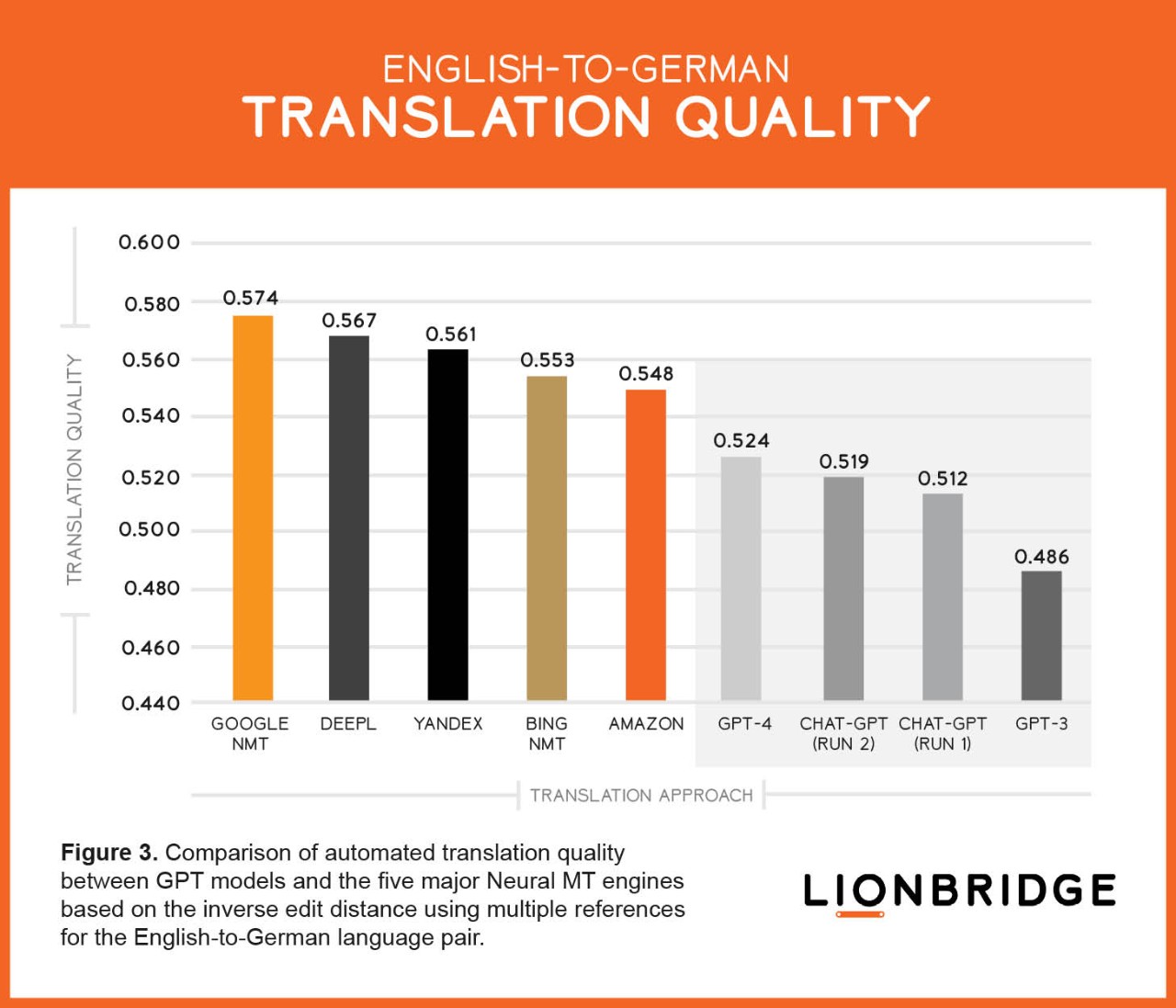
The translation results for the English-to-Spanish and English-to-German language pairs are shown respectively in Figures 2 and 3. In these two scenarios, all the Neural MT engines performed better than the LLMs, as has been the case to date.
As we expected, the better the GPT model, the better the MT results, with GPT-4 outperforming ChatGPT and GPT-3.
Can I Trust Large Language Models for the Professional Use of My Translations?
Generative AI is still in its early stages and has not fully evolved. As such, it falls short in some key areas. Our ChatGPT and localization whitepaper highlights how the technology fails to tell the truth, has no clue, and can’t count. Ready to rely on it? Slow down.
Shortcomings should give enterprises some pause for concern.

Variability
Our evaluation demonstrates that GPT outputs are variable. In other words, results may change from run to run. You can see this phenomenon in Figures 2 and 3, whereby run one and run two have different results.
We expected this outcome. Nonetheless, this variability is essential when weighing whether to use LLMs for professional translation as predictivity is paramount.
There is little room for randomness when companies translate their content. MT output must be more deterministic than what generative AI currently offers. Consistency is expected in professional MT, and other LLM uses for professional purposes.
Pure deterministic results go against the nature of generative models, in which a level of, let’s say, creativity or variability is supposed and assumed. This situation is okay and even desirable for certain cases, but not all. A mechanism to control variability (beyond the use of the “Temperature” setting, i.e., the setting that is supposed to control LLM “creativity”) is essential.
The best approach to control variability in generative models is not yet apparent. Perhaps users can address this problem through some predefined prompts and a combination of settings for specific tasks, but a more concrete solution will be necessary.
Lack of predictivity does not match well with a good part of business applications.
API instability
Another current issue with LLMs is Application Programming Interface (API) instability.
Most generative AI applications are still in the early phases of their deployment. A huge demand causes massive use of its API. The combination of these factors creates problems. This situation is evident as people experience more issues with these applications than with other, more mature technologies.
Errors
We have found accuracy issues in the LLM MT output that are either not present in the NMT output or are present but in a much lower percentage.
These issues include hallucinations, which are invented terms or terms that don’t appear in the source text, or problems with concordance, which pertain to agreement within the text. (This may include an adjective or determiner in the feminine grammatical gender paired with a noun in the masculine grammatical gender or vice versa.)
As shown in Table 1, the LLM used the rare and possibly too colloquial word “marketeros” in the Spanish target during the translation. An accurate translation is the term “responsables del marketing”. The LLMs made similar mistakes in the German and Chinese target languages. It is especially important to monitor for MT catastrophic errors as brands can face reputational, financial, or legal repercussions, depending on the severity of the error.
Table 1. Examples of “Invented” or “Hallucinated” Terms in LLM MT Output:
- English-to-Spanish (EN-ES)
- English-to-German (EN-DE)
- English-to-Chinese (EN-ZH)
| Source | As marketers, we all aspire to surprise, delight, and connect to a global and thriving culture. |
|---|---|
| Target | Como marketeros, todos aspiramos a sorprender, deleitar y conectarnos con una cultura global y próspera. |
| Comment | should be: “responsables del marketing” |
| Source | Tax on interest, discounts & other items of gross income paid to finance companies & other financial intermediaries not performing quasi-banking functions |
|---|---|
| Target | Steuer auf Zinsen, Rabatte und andere Posten des Bruttoeinkommens, die an Finanzunternehmen und andere Finanzintermediäre gezahlt werden, die keine quasibankähnlichen Funktionen ausüben. |
| Comment | should be: "Vermittler" and "bankähnlichen" |
| Source | See how Honda used Twitter's Instant Win feature for a good cause while also earning lifts in purchase intent and brand favorability. |
|---|---|
| Target | 看看本田如何利用推特的即时赢取功能为一个好事业赢得提升,同时也获得购买意向和品牌可喜度的提升。 |
| Comment | should be: "公益事业" and "好感度" |
| Language | Source | Target | Comment |
|---|---|---|---|
| English-to-Spanish (EN-ES) | As marketers, we all aspire to surprise, delight, and connect to a global and thriving culture. | Como marketeros, todos aspiramos a sorprender, deleitar y conectarnos con una cultura global y próspera. | should be: “responsables del marketing” |
| English-to-German (EN-DE) | Tax on interest, discounts & other items of gross income paid to finance companies & other financial intermediaries not performing quasi-banking functions | Steuer auf Zinsen, Rabatte und andere Posten des Bruttoeinkommens, die an Finanzunternehmen und andere Finanzintermediäre gezahlt werden, die keine quasibankähnlichen Funktionen ausüben. | should be: "Vermittler" and "bankähnlichen" |
| English-to-Chinese (EN-ZH) | See how Honda used Twitter's Instant Win feature for a good cause while also earning lifts in purchase intent and brand favorability. | 看看本田如何利用推特的即时赢取功能为一个好事业赢得提升,同时也获得购买意向和品牌可喜度的提升。 | should be: "公益事业" and "好感度" |
As shown in Table 2, the LLM made agreement or character errors when translating into all three of our target languages. For example, it provided the feminine version of the word “other” in Spanish when it should have been the masculine form. These types of mistakes can potentially erode consumers’ confidence in brands.
Table 2. Examples of Agreement and Character Errors.
- English-to-Spanish (EN-ES)
- English-to-German (EN-DE)
- English-to-Chinese (EN-ZH)
| Category | Agreement error |
|---|---|
| Source | The centre for urban culture is one of the best concert venues in the city and regularly hosts the most famous performers of indie rock, electronic music, metal and other genres of modern urban music. |
| Target | El centro de cultura urbana es uno de los mejores lugares de conciertos de la ciudad y regularmente acoge a los artistas más famosos del rock independiente, la música electrónica, el metal y otras géneros de música urbana moderna. |
| Comment | should be masculine (“otros”) |
| Category | Agreement error |
|---|---|
| Source | Do not use harsh chemicals, cleaning solvents, or strong detergents to clean the programmer and wand. |
| Target | Verwenden Sie keine aggressiven Chemikalien, Reinigungslösungsmittel oder starken Reinigern, um den Programmierer und den Stab zu reinigen. |
| Comment | should be indefinite accusative ("Reiniger") |
| Category | Script error |
|---|---|
| Source | Handle the fiber with care as damage may occur if struck or bent sharply. |
| Target | 小心處理纖維,因為如果受到撞擊或急劇彎曲可能會損壞。 |
| Comment | Traditional Chinese characters |
| Category | Language | Source | Target | Comment |
|---|---|---|---|---|
| Agreement error | English-to-Spanish (EN-ES) | The centre for urban culture is one of the best concert venues in the city and regularly hosts the most famous performers of indie rock, electronic music, metal and other genres of modern urban music. | El centro de cultura urbana es uno de los mejores lugares de conciertos de la ciudad y regularmente acoge a los artistas más famosos del rock independiente, la música electrónica, el metal y otras géneros de música urbana moderna. | should be masculine (“otros”) |
| Agreement error | English-to-German (EN-DE) | Do not use harsh chemicals, cleaning solvents, or strong detergents to clean the programmer and wand. | Verwenden Sie keine aggressiven Chemikalien, Reinigungslösungsmittel oder starken Reinigern, um den Programmierer und den Stab zu reinigen. | should be indefinite accusative ("Reiniger") |
| Script error | English-to-Chinese (EN-ZH) | Handle the fiber with care as damage may occur if struck or bent sharply. | 小心處理纖維,因為如果受到撞擊或急劇彎曲可能會損壞。 | Traditional Chinese characters |
The Verdict: Is It the Beginning of the End of the NMT Paradigm?
It’s not the beginning of the end of the NMT paradigm; as indicated, the signs that NMT has matured, and the likelihood of an MT paradigm shift have been present for some time. We are now on a continuum toward that end.
We began questioning whether the paradigm’s predominance in its current form was coming to an end after noticing the quality of the top five NMT engines was starting to be flat, without major improvements, as demonstrated in Figure 4, which measures the output quality of the top five NMT engines between May 2018 and December 2022 for German, Spanish, Russian, and Chinese using the inverse edit distance.
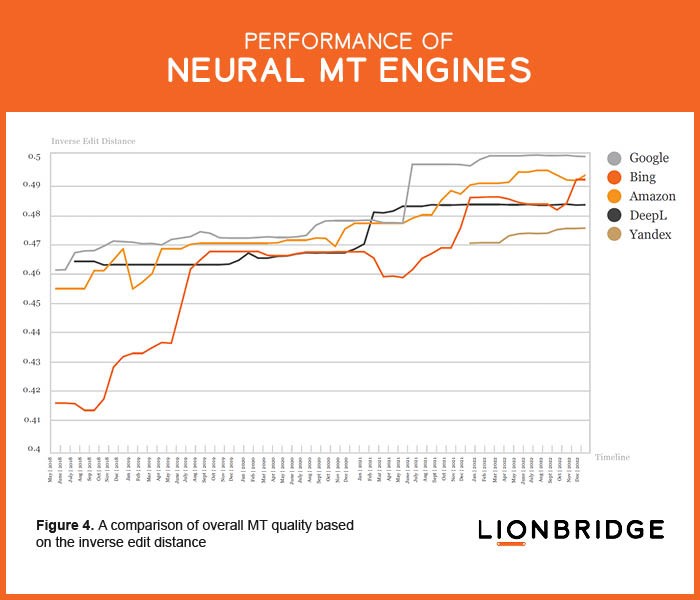
Little quality improvement during 2022 led us to conclude that NMT hit a plateau as a similar occurrence transpired at the end of MT’s previous central paradigm, the statistical paradigm. The Lionbridge Machine Translation Tracker — the industry’s longest-standing measure of the major MT engines — provides additional insight into the performance of the five NMT engines.
While the latest advancement in translation quality by a generative AI model may further advance the end of the NMT paradigm as we know it, the technology still has a long way to go.
It is worth underscoring that generative AI applications are still in the early phases of their deployment. Problems, such as the ones we highlighted above must be resolved and are being resolved. We are already seeing improvements being made at breathtaking speed. In our latest tests on ChatGPT-4, some of those issues have been fixed. The incredible speed at which LLMs can improve supports the notion that LLMs will become the next paradigm for Machine Translation.
More likely than not, we expect Neural MT providers to integrate some aspects of LLMs into the NMT architecture rather than LLMs overtaking the current paradigm altogether as the paradigm evolves. We’ve seen similar hybrid periods when the MT industry segued from Rule-based MT (RBMT) to Statistical MT (SMT).
Are Translators Impressed With Generative AI’s Translation Performance?
What does the human translator think of generative AI? Because of its current shortcomings, human evaluators, who compared the performance between Neural MT engines and LLMs, indicated they still prefer Neural MT output over the output of LLMs. Evaluators have consistently expressed this preference, including those assessing Chinese output.
There is no doubt that generative AI will continue to evolve, and we will help you stay abreast of the rapidly changing advancements.
Get in touch
Read our blog to learn more about our take on ChatGTP’s translation performance and what it says about the future of localization.
If you’d like to explore how Lionbridge can help you effectively use Machine Translation, contact us today.
