- 服務內容


- 產業

- 資源


服務內容首頁
生成式 AI
- AI 翻譯服務
- Content Remix
AI 訓練
- Aurora AI Studio™
機器翻譯
- MT 追蹤工具
Smart Onboarding
翻譯服務模式
內容服務
- 技術文件編寫
- 訓練與線上學習
- 財務報告
- 數位行銷
- SEO 與內容最佳化
翻譯服務
- 影音內容本地化
- 軟體本地化
- 網站本地化
- 受監管公司適用的翻譯服務
- 口譯
- 現場活動
- Lionbridge Language Quality Services
測試服務
- 功能品管與測試
- 相容性測試
- 互操作性測試
- 效能測試
- 輔助使用性測試
- 使用者體驗 / 客戶體驗測試
![]()
選擇語言:

儘管生成式 AI 具有顛覆性的影響,機器翻譯技術仍保有其實用價值
變革即將來臨:了解自動翻譯的發展
我們這麼說已經有好一陣子了:機器翻譯 (MT) 典範快要功成身退,顛覆變革即將來臨。歡迎繼續閱讀我們的專家評論,一窺究竟。
Lionbridge 自動翻譯專家就多個議題大方分享深入見解,包括:
- MT 引擎與生成式 AI (GenAI) 模型在特定時間點的翻譯表現,以及從宏觀脈絡看這些結果代表什麼意義
- 自動翻譯工具的侷限
- 增進機器翻譯成效的一些方法
當您越了解 MT 和 GenAI,就越能根據自己的需求選擇部署合適的工具,充分發揮各個典範的長處,進而提升翻譯效率、增加內容輸出量並節省成本。
精選 Lionbridge 專家評論
GPT-4 值得注意的不尋常表現,2023 年 10 月
有鑑於生成式 AI (GenAI)/大型語言模型 (LLM) 的盛行與興起,我們亦順應潮流改善了 Lionbridge 機器翻譯 (MT) 品質追蹤工具報告。 從此之後,報告中除了 GPT-3.5 與 Davinci 的結果以及神經 MT (NMT) 引擎的表現外,也會將 GPT-4 翻譯結果納入分析。
我們的最新分析得出哪些結果? GPT-4 有些值得注意的不尋常表現。
我們遇到了幾個與 GPT-4 相關的問題,包括效能緩慢、基於多種不同原因無法提供翻譯,以及行為不一致,例如有的執行有漏譯但其他執行則沒有。
分析結果 #1 — GPT-4 無法翻譯某些文字。
GPT-4 無法翻譯我們 MT 測試集中的某個特定句子。
做了些調查後,我們判斷應該是某個詞彙在特定脈絡下會有性方面的意涵,因此造成這個問題。 必須要澄清的是,我們測試集中的這個句子,是完全符合標準且可接受的。 然而,這個詞仍舊觸發了 GPT-4 的性相關內容過濾功能,導致 AI 在審查該句子後決定不輸出其翻譯。 這個結果讓我們頗感意外,有兩個原因:
單獨來看,該詞彙的一般字義並沒有什麼問題。
從前後文來看,該句子也不會有什麼不妥的解釋。
這個觀察結果讓我們得出結論,GPT-4 的內容過濾機制有部分可能是採用簡單的禁用字詞清單,而其中也包含了一些有歧義的字詞。 這種作法的問題在於,它很容易會反應過度而造成錯誤辨識,這對專業翻譯而言是很嚴重的問題。
由於先前的機器翻譯技術,例如神經 MT 引擎等,並未出現過這種類型的內容過濾問題,因此我們推斷這是 LLM 技術的一項侷限。
但現實世界的一些情況會受到這個侷限影響。 舉例來說,假設您需要翻譯與婦科或是性教育相關的醫學內容, 很可能會訝異地發現有些內容不會被 LLM 翻譯。
有趣的是,只有在將這個句子翻譯至中文這個特定語言時,我們才會遇到這個問題,翻譯至其他語言則不會。 而這也顯示 GPT-4 是對輸出進行內容過濾。 解決這個問題的辦法,就是在進行翻譯任務時關閉內容過濾功能。
分析結果 #2 — GPT-4 輸出的變異性。
追蹤翻譯表現五個星期後,我們發現 LLM 機器翻譯輸出的變異性非常大,尤其是 GPT-4。
我們本來就預料到生成式 AI 會有這種結果,但即使透過溫度 (Temperature) 以及最高機率 (Top Probability,Top_p) 等參數設定來降低創意程度,試圖讓輸出更加確切一致,所得到結果的變異性還是遠比我們預測的來得高。 就算是執行完一次翻譯後緊接著馬上再執行一次,每一次 GPT 執行所得到的翻譯輸出也都不一樣。
這兩個翻譯雖然不一樣,但都是可接受的結果。 然而,這是另一層面的控制,也是它與前一個神經 MT 典範的另一個不同之處。
我們開始直覺地體認到,從 NMT 轉變為 LLM MT 典範這個可能的變革,或許不光是技術上的變革,還更需要改變我們的思維: 我們可能得做好心理準備,接受就算使用完全一樣的輸入以及參數,也可能會得到沒那麼確切一致的輸出,此外結果的變異性也會比目前慣常使用的自動化作業來得高。
雖然我們在某種程度上得接受不確定性的增加,但或許也能利用一些機制和最佳實務做法,稍加控制這種變異性。
最後,在檢視圖表時,請注意 GPT-4 編輯更動程度線條的下降,並不代表其品質下降, 這只是反映了 GPT 輸出的變異性罷了。 在下個月的報告中,就可能看到它往上走。 歡迎關注這裡,了解相關發展及更多深入見解。

—Lionbridge 創新副總裁 Rafa Moral
專家評論主題索引
瀏覽下方的執行摘要,探索我們之前的專家評論主題。
2023 年 3 月 — 某個大型語言模型 (LLM) 表現勝過某個神經機器翻譯 (MT) 引擎: 後續將如何發展?
2023 年 2 月 — 提升機器翻譯 (MT) 的品質:MT 自訂或 MT 訓練
2023 年 1 月 — ChatGPT 與主流 MT 引擎的翻譯品質比較
2022 年 11 月 — Microsoft MT 改善
2022 年 10 月 — MT 和語言正式度
2022 年 9 月 — 運用術語提升 MT 輸出的品質
2022 年 8 月 — 克服 MT 作業產生的嚴重錯誤
2022 年 7 月 — MT 語言排名
2022 年 6 月 — 正確分析 MT 品質
2022 年 5 月 — Amazon 與 Yandex 的 5 月表現
2022 年 4 月 — Yandex 的 4 月表現
2022 年 3 月 — 客製化 MT 比較評估
2022 年 2 月 — 神經機器翻譯 (NMT) 的未來
2022 年 1 月 — MT 引擎 1 月表現
2021 年 12 月 — Lionbridge 在 MT 品質追蹤工具中新增 Yandex MT,以進行競爭力評比
2021 年 11 月 — Bing 翻譯工具有所改良
2021 年 10 月 — Amazon 的 MT 引擎如何不斷進步
2021 年 9 月 — Amazon 對 MT 品質進行改善
2021 年 8 月 — 龍頭科技公司及其 MT 引擎發展
Lionbridge 專家評論
閱讀我們自動翻譯專家大方分享的深入見解。
2023 年 3 月
生成式人工智慧 (AI) 已經達成一個重大的里程碑: 在我們的一個比較評估中,它的表現超越了某個神經機器翻譯 (MT) 引擎。 更明確地說,大型語言模型 (LLM) GPT-4 在英譯簡中這個語言組合上,品質表現略高於 Yandex (如圖 1 所示)。
這個發展之所以值得注意,是因為自神經 MT 問世以來,這是頭一次有不同類型的 MT 方法勝過某個神經 MT 引擎。除此之外,勝過神經 MT 引擎的是一個非 MT 方法,它不是專為機器翻譯所設計,而是個多用途的語言自動化功能。

為何您應該要留意這個事件? 如果您是 MT 供應商,為了保持競爭力,自然必須站在科技進展的最前線,並思考它們對您目前的 MT 服務會有什麼影響。 如果您是 MT 採購者,則必須通透了解這些進展,以便做出明智的 MT 投資,而納入部分 LLM 技術而非單純使用神經 MT 服務,很可能會是未來的趨勢。
值得注意的是,生成式 AI 還在開發的初期階段, 也因此,它在一些重要領域上仍舊非常不足。 舉例來說,它多次執行所產出的輸出是變動的;它在應用程式開發介面 (API) 上有不穩定性方面的問題;此外,它的錯誤也比神經 MT 引擎來得多。 這些問題必須要加以解決,這個技術才可能成熟,而我們也已經看到他們以驚人的速度做出不少進展。
LLM 驚人的進步速度也讓這樣的論點更具說服力:LLM 將會成為機器翻譯的下一個典範。 我們認為會有一個混合使用的時期,也就是隨著典範的演進,神經 MT 供應商會將 LLM 的一些層面整合至神經 MT 架構中。
歡迎閱讀我們的部落格文章,了解神經 MT 與 LLM 在另外兩個語言組合上的翻譯品質比較,以及我們對這是否是神經機器翻譯典範開始走向結束的看法。

—Lionbridge 創新副總裁 Rafa Moral
2023 年 2 月
對於想將翻譯作業自動化的公司而言,常見機器翻譯 (MT) 引擎的輸出結果通常已經足夠因應需求。 然而,這些引擎也可能會產出品質不佳的結果,尤其是處理技術性或高度專業的內容時,這種傾向會更明顯。
如果公司想改進機器翻譯 (MT) 的結果以求達成特定目標,可以考慮以下兩個選項: MT 自訂和/或 MT 訓練。 無論使用哪一種方法,還是將兩者結合在一起,都有助自動化翻譯流程產出更好的結果。
然而,這兩種作法並不相同,因此無法互相替代。 表 1 大概說明了 MT 自訂與 MT 訓練,並就評量各個方式時可考量的因素提供一些建議。
機器翻譯自訂與機器翻譯訓練
- MT 自訂
- MT 訓練
| MT 自訂 | |
|---|---|
| 意義及運作方式 | 使用詞彙表及「請勿翻譯」(DNT) 清單來調整既有的機器翻譯引擎,藉此改善機器生成翻譯的正確性 |
| 功用 | 改善 MT 的翻譯建議,產出更正確的輸出並減少對譯後編修的需求 |
| 特有好處 | 能讓公司保持其品牌名稱、遵循所應使用的術語,並顧及地區性差異 |
| 使用的風險 | 如果執行不當,MT 可能會產出品質不佳的翻譯建議,對整體品質帶來負面影響 |
| 使用時機 | 非常適合技術性以及講究細節的內容,以及有以下要求的任何內容: *正確的術語翻譯 *地區性差異,但缺乏足夠的資料進行 MT 訓練 |
| 成功要素 | 由經驗豐富的 MT 專家,為您成功管理輸入與輸出正規化規則、詞彙表和 DNT |
| 成本考量 | 更新 MT 所用的設定檔會有個一次性支付的成本,日後也需要隨時間維護詞彙表;若將潛在好處納入考量,成本相對而言並不昂貴,而且通常比 MT 訓練的成本來得低 |
表 1. MT 自訂與 MT 訓練之比較
| MT 訓練 | |
|---|---|
| 意義及運作方式 | 使用來自語料庫及翻譯記憶庫 (TM) 的龐大雙語資料,來建置與訓練 MT 引擎,藉此改善機器生成翻譯的正確性 |
| 功用 | 改善 MT 的翻譯建議,產出更正確的輸出並減少對譯後編修的需求 |
| 特有好處 | 能讓公司展現特有的品牌調性、語氣和風格,並顧及地區性差異 |
| 使用的風險 | 如果沒有足夠的資料來訓練引擎,MT 訓練可能無法對輸出有任何影響;如果編寫人員經驗不足,使用太多不必要的術語,可能會導致 MT 產出品質不佳的翻譯建議,對整體品質帶來負面影響 |
| 使用時機 | 非常適合高度專業的內容、行銷與創意內容,以及有以下要求的任何內容: *特有的品牌調性、語氣或風格 *地區性差異,且有足夠的資料進行 MT 訓練 |
| 成功要素 | 要有最低 15K 獨特不重複的句段,才足以訓練引擎 |
| 成本考量 | 成本包括初次訓練及後續訓練的成本,如果 MT 表現監測顯示還有改進的空間,成本亦會隨時間增加;若將潛在好處納入考量,MT 訓練對特定案例會是值回票價的投資 |
表 1. MT 自訂與 MT 訓練之比較
| MT 自訂 | MT 訓練 | |
|---|---|---|
| 意義及運作方式 | 使用詞彙表及「請勿翻譯」(DNT) 清單來調整既有的機器翻譯引擎,藉此改善機器生成翻譯的正確性 | 使用來自語料庫及翻譯記憶庫 (TM) 的龐大雙語資料,來建置與訓練 MT 引擎,藉此改善機器生成翻譯的正確性 |
| 功用 | 改善 MT 的翻譯建議,產出更正確的輸出並減少對譯後編修的需求 | 改善 MT 的翻譯建議,產出更正確的輸出並減少對譯後編修的需求 |
| 特有好處 | 能讓公司保持其品牌名稱、遵循所應使用的術語,並顧及地區性差異 | 能讓公司展現特有的品牌調性、語氣和風格,並顧及地區性差異 |
| 使用的風險 | 如果執行不當,MT 可能會產出品質不佳的翻譯建議,對整體品質帶來負面影響 | 如果沒有足夠的資料來訓練引擎,MT 訓練可能無法對輸出有任何影響;如果編寫人員經驗不足,使用太多不必要的術語,可能會導致 MT 產出品質不佳的翻譯建議,對整體品質帶來負面影響 |
| 使用時機 | 非常適合技術性以及講究細節的內容,以及有以下要求的任何內容: *正確的術語翻譯 *地區性差異,但缺乏足夠的資料進行 MT 訓練 |
非常適合高度專業的內容、行銷與創意內容,以及有以下要求的任何內容: *特有的品牌調性、語氣或風格 *地區性差異,且有足夠的資料進行 MT 訓練 |
| 成功要素 | 由經驗豐富的 MT 專家,為您成功管理輸入與輸出正規化規則、詞彙表和 DNT | 要有最低 15K 獨特不重複的句段,才足以訓練引擎 |
| 成本考量 | 更新 MT 所用的設定檔會有個一次性支付的成本,日後也需要隨時間維護詞彙表;若將潛在好處納入考量,成本相對而言並不昂貴,而且通常比 MT 訓練的成本來得低 | 成本包括初次訓練及後續訓練的成本,如果 MT 表現監測顯示還有改進的空間,成本亦會隨時間增加;若將潛在好處納入考量,MT 訓練對特定案例會是值回票價的投資 |
表 1. MT 自訂與 MT 訓練之比較
歡迎閱讀我們的部落格文章,深入了解機器翻譯自訂與機器翻譯訓練。

—Thomas McCarthy,Lionbridge MT 業務分析師
2023 年 1 月
對機器翻譯 (MT) 來說,大型語言模型 (LLM) 會是神經機器翻譯 (NMT) 之外的另一個可能典範嗎? 為了找出這個問題的答案,我們將 OpenAI 最新的 LLM,也就是 GPT-3 系列的ChatGPT,與我們機器翻譯追蹤工具中使用的五大主流 MT 引擎,就其翻譯表現進行比較。
一如預期,專業化 NMT 引擎的翻譯表現優於 ChatGPT。 但令人驚訝的是,ChatGPT 的表現其實挺不錯的。 如圖 1 所示,ChatGPT 的成果非常接近專業化引擎。
為了評估翻譯的品質層級,我們選用英文譯至西文這個語言組合的多個參考翻譯來計算編輯更動程度,又名反向編輯距離 (inverse edit distance)。 編輯更動程度評量的是編譯人員為了取得與人工翻譯一樣的高品質結果,而對 MT 輸出所做的編輯更動次數。 在計算時,我們會將原始的 MT 輸出,與 10 個 (而非僅只 1 個) 不同的人工翻譯 (也就是多個參考翻譯) 相比較, 所得的反向編輯距離越高,代表品質越好。
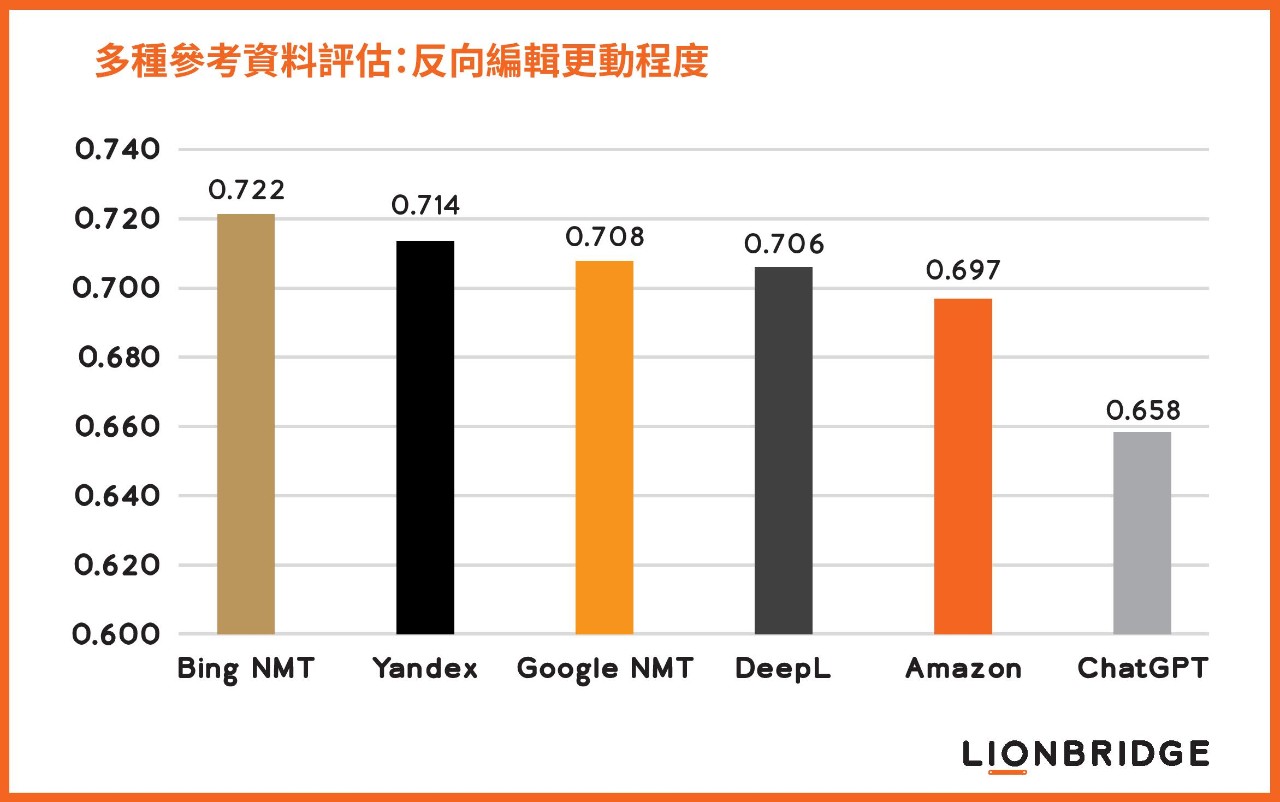
圖 1. 根據英翻西這個語言組合的多個參考翻譯計算反向編輯距離,比較 ChatGPT 與主流機器翻譯引擎的自動翻譯品質。
這些結果非常值得我們注意,因為這個通用模型是訓練用以執行自然語言處理 (NLP) 任務,並未特地受過執行翻譯的訓練。 而 ChatGPT 的表現,已經接近高品質 MT 引擎在兩、三年前的成績了。
從大眾的關注與科技公司對這個技術的大量投資,都可看出 LLM 有長足的進步,因此我們應該很快就能知道,究竟是 ChatGPT 會超越 MT 引擎,還是 MT 將開始採用新的 LLM 典範。 MT 或許會以 LLM 為基礎,但針對機器翻譯微調這項技術。 這會很像 OpenAI 及其他 LLM 公司目前的作法,也就是針對特定使用案例去改進他們的通用模型,例如讓機器能以對話聊天的方式與人類溝通。 至於專業化則可進一步讓所執行的任務更加準確。
這些大型語言「通用」模型的一個好處,是它們可以執行很多不同的任務,而且多數時候都能提供卓越的品質。 舉例來說,另一個通用智慧模型,DeepMind 的 GATO,便曾做過超過 600 種任務的測試,並在其中 400 種取得最先進 (SOTA) 結果。
這樣看來,將有兩個開發路線會繼續存在,一個是像 GPT、Megatron 和 GATO 這類通用模型,另一個則是以通用模型為基礎再針對特定用途加以專業化的模型。 通用模型對推進「通用人工智慧」(AGI) 非常重要,以長程來看甚至可望催生更令人期待的發展。 專業化模型則能在短期內於特定領域中發揮實際功用。 而 LLM 令人讚嘆的其中一點,就是它可以同時參與這兩個路線的發展。
對於未來,我們非常期待, 也將會繼續評估 LLM 並發表結果,讓各位可以掌握這個令人振奮演進的最新狀況。 歡迎閱讀我們的部落格,深入探究 ChatGPT 的翻譯表現,並進一步了解 ChatGTP 與本地化以及它為何可能徹底改變本地化產業。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 11 月
從 10 月 11 日到 11 月 1 日,Microsoft 的機器翻譯結果整體上的進步幅度不錯。有鑑於 Bing 翻譯工具近期的品質提升,所有主要 MT 引擎產出的結果可說是都不相上下, 因此,MT 引擎間取得領先地位的爭奪戰也會更加激烈。
主流 MT 引擎已經有幾個月沒有什麼值得關注的進展, 希望 Microsoft 這次的改善能突破停滯不前的瓶頸,推動這些引擎突飛猛進。
這次我們不只像以往只使用單一個參考翻譯進行評量,還用包含多個參考翻譯的方法進行第二次追蹤分析,確認 Microsoft 確實有所改善。 在這次 MT 評估中,我們使用了 10 個 (而非一個參考翻譯) 由譯者完成的參考翻譯做為黃金標準,將最終結果中多種可能的正確翻譯納入考量,取得更為精確的「編輯更動程度」評估。
隨著年末將近,我們注意到 2022 年 MT 結果的表現非常平淡, 觀察到的變化並不多;而這次 Microsoft Bing MT 的進展,可能是這一整年中最顯著的進步了。 正如今年稍早的評論,目前 MT 典範可能已經達到頂點, 我們期待 2023 年機器翻譯能有更進一步的發展。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 10 月
這個月,我們想帶領您了解語言的正式度 (Formality),以及在使用機器翻譯 (MT) 時妥善處理這類問題的困難度有多大 (然而使用 MT 處理並非不可能)。
使用機器翻譯 (MT) 引擎時,您可能會在語言正式度這方面得到錯誤且不一致的結果。 理由何在? 一般而言,MT 模型會為輸入的每個分段文句傳回一個翻譯。 但若是輸入的分段文句有岐義時,模型就必須在數個有效選項中擇一輸出,而不會考量目標對象是誰。 而任由模型在不同的有效選項中選擇,就可能會造成翻譯不一致,或是翻譯的正式度有誤。
如果來源語言的正式度級別較目標語言來得少,就更難以得到正確的輸出成果。 舉例來說,有些語言具有明確定義的敬稱,例如法文的 tu (你) 或 vous (您),但英文則沒有。
雖然多數的 MT 系統並不支援語言正式度或性別參數,但我們仍舊看到一些進展。 目前,DeepL (API) 和 Amazon (主控台及 SDK) 均提供可調整正式度的功能。 而 Lionbridge 的企業級機器翻譯解決方案 Smart MT™,則可以設定語言規則並套用至目標文本,以便依照所需的風格或正式度生成機器翻譯結果。
為了滿足您目標對象的需求,您必須有效地翻譯原文,而這也包括要解決 MT 輸出中正式或非正式用語的問題。 畢竟那些讓人感覺「不太對勁」或甚至無禮的翻譯,可能會讓目標對象對您敬而遠之。
歡迎閱讀我們的部落格文章,深入了解 MT 以及正式與非正式用語。

—Lionbridge MT 專員 Yolanda Martin
2022 年 9 月
使用機器翻譯 (MT) 儘管有許多優點,但也必須審慎進行。 常見 MT 引擎輸出的翻譯有時會有不少錯誤,尤其是應用在特定領域上時,在術語方面可能會產生不如人意的結果, 如果是醫療或法律領域,更有可能因此造成嚴重的傷害。 但您可以透過一些方式來提升 MT 輸出的品質。
使用術語可以改善 MT 的品質,生成正確又一致的翻譯。
請務必使用含有特定領域專門術語的雙語文本,來訓練客製化的 MT 系統。 但是,如果在訓練引擎用的專門文本中,使用的術語並不一致,那麼也還是無法保證能產出正確的翻譯。 這個領域的相關研究建議,可以透過註解的方式將語言學資訊輸入神經機器翻譯 (NMT) 系統中。 至於要以人工還是半自動的方式實行註解,則取決於可用資源 (例如詞彙表) 以及限制條件 (例如時間、成本及可用註解人員等) 而定。
使用 Lionbridge 的 Smart MT™,您不但可以設定語言規則並套用至來源與目標文字,也可以將「請勿翻譯」(DNT) 及詞彙表清單加入特定的設定檔,再據此進行術語管理。 我們會協助客戶建立與維護詞彙表,並定期調整以加入新的相關詞彙和汰除過時的術語。 此外,只要在 Smart MT 建立詞彙表,就能將它們使用於所有的 MT 引擎,進一步節省時間與金錢。
在 MT 專案中使用詞彙表,並不像表面看來那麼簡單。 詞彙表如果使用不當,反而會對機器翻譯的整體品質造成負面影響。 如果希望 MT 生成的翻譯能使用所提供的術語,最好的作法就是透過 MT 訓練。 訓練 MT 引擎、客製化詞彙表,再加上制訂前處理及後處理的規則,將有助確保 MT 輸出使用正確的術語,並展現與客戶文件相近的風格。
歡迎閱讀我們的部落格文章,深入了解如何運用術語提升 MT 輸出的品質。

—Lionbridge MT 專員 Yolanda Martin
2022 年 8 月
隨著公司日漸仰賴機器翻譯 (MT) 做為標準實務做法,員工也必須避免重大錯誤的傳播。
一般的 MT 錯誤是跟語言特徵有關的錯誤,例如拼寫、文法或標點符號等,然而重大錯誤比這類錯誤更加嚴重。 重大錯誤往往超出語言學範疇,是指引擎的輸出內容大幅偏離了原文訊息的意圖, 這類內容產生的錯誤資訊或誤解,可能會為企業帶來聲譽、財務或法律上的負面影響,甚至對公共安全或公共衛生產生不良後果。 因此,設法辨識並找出這類錯誤,阻止它們危及您的溝通,也就非常重要。
Lionbridge 會對翻譯文本特別執行自動品質檢查,一方面是為了偵測重大錯誤,一方面也能保持 MT 作業速度並減少人工干預的需要。
這些自動化方法可以偵測以下事項:
- 譯文與原文意思相反
- 冒犯、粗俗或極為敏感的字詞
- 既是常用字詞也是個人或組織專有名詞的翻譯錯誤
電腦科學家會持續不斷改善現有 MT 技術來避免這些翻譯錯誤,因此公司遇到重大錯誤的情形也會隨之減少。 但在此之前,我們可以在翻譯流程中運用自動化技術,辨別可能的問題、修正有問題的字句並增進正確度。
閱讀我們的部落格文章,進一步了解機器翻譯會產生的嚴重錯誤。

—MT 小組負責人 Luis Javier Santiago

和 Lionbridge 創新副總裁 Rafa Moral
2022 年 7 月
Google NMT、Bing NMT、Amazon、DeepL、Yandex — 哪一種引擎最好? 從上個月的資料以及目前的一般趨勢來看,這些主流引擎的表現其實相差無幾。 正因如此,您在研發 MT 策略時更應該加入其他因素一起考量,例如哪一種 MT 引擎可更輕易翻譯特定的語言組合。
了解不同引擎處理特定語言組合的難易程度,您在規劃各個語言的翻譯費用時,就能更妥善地分配預算。舉例來說,處理複雜的語言組合時,您就需要分配更多資源與心力才能取得高品質翻譯。因此,對語言的複雜性有深入了解,會有助您做出更明智的商務決策。
依照可譯性來排序語言不是個簡單直覺的流程;然而,我們可以使用不同的指標來進行評估。編輯更動程度,也就是譯後編修人員為確保最終譯文擁有與人工翻譯相同的品質,而對機器翻譯之內容所做的更動次數,就有助於我們了解各個語言組合的 MT 複雜性和可譯性 (機器可譯性或 M 可譯性)。
當譯出語為英文時,多數羅曼語系的語言,例如葡萄牙文、西班牙文、法文和義大利文等,通常只要稍做修改就能得到高品質的譯文。我們發現這些目標語言是機器最能輕鬆處理的語言,它們也名列我們 M 可譯性排名的前四名。 匈牙利文和芬蘭文這兩個烏拉爾語系的語言,則屬於較為複雜的語言,因而在我們的可譯性排名中墊底,分別是第 27 和第 28 名。 另一個同一語系的愛沙尼亞文,也屬於較為複雜的語言。這些根據 Lionbridge 處理過的數百萬個句子分析所得的結果,可以看出語系對 MT 產出結果的重要性。
雖然同語言內的比較仍有其侷限,但這樣的排名能提供一些有趣的深入見解,協助您更有效地管理多語言專案。閱讀我們的部落格,查看完整的 Lionbridge 語言排名表。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 6 月
在 6 月,我們觀察到 Yandex MT 引擎的俄語翻譯有小幅進步,而 Microsoft Bing MT 引擎的翻譯成效則有些微退步。 這些是值得注意的改變,還是無關緊要的結果? 為進一步釐清,我們以不同方式分析了翻譯成效。
相較於使用單一嚴格標準來衡量 MT 翻譯和「完美」人工翻譯的差距,我們使用多種參考翻譯。 我們將每筆機器翻譯與 10 筆專業譯者的翻譯相互比較。 當我們採取這項做法時,Yandex 和 Microsoft Bing 在 6 月出現的翻譯品質小幅波動就不復存在。 有鑑於此,我們可以下個結論,就是 MT 翻譯品質並沒有改變; 6 月成效持平。
有時,資料以及根據資料繪製的圖表可能會有誤導之虞。 由於不同量測方法之間通常會有些許誤差,使得這類情況經常發生。 因此,使用一種以上的方法來評估資料,會是準確解讀成效的良好做法。
我們預期未來幾個月內,MT 引擎的品質將繼續持平。 我們將在此提供分析和對 MT 的整體觀察。 下個月,敬請期待對不同 MT 語言配對進行的比較。 我們將探討運用資料按 MT 複雜性來分類語言和語系的可行性,並判斷機器是否較為擅長翻譯某些語言配對。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 5 月
對 MT 引擎來說,大體而言,這又是波瀾不興的一個月。
我們注意到,Amazon 在處理英文譯至西班牙文這個組合上的表現有進步, 目前已成為這個語言組合表現最佳的引擎。 其實 Amazon 在其他語言上也有微幅進展,只是程度都沒有英文譯至西班牙文這個組合來得大。 我們推測這些進步是出於某些一般設定的變更,以及對英文譯至西班牙文這個組合所投入的心力。 這些改進似乎影響了某些特殊字元,與含有度量衡表示之字串的處理方式。
Yandex 連續兩個月出現微幅改善, 有趣的是,這些改善也影響到西班牙文。
如前所述,這個月並沒有什麼明顯的變化, 所有引擎的表現都相差無幾。 接下來的幾個月,我們將針對一些特定的 MT 領域進行分析,並提供整體而言觀察到的結果, 當然同時也會繼續追蹤重要的發展。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 4 月
Yandex 的 MT 引擎效能數個月以來都沒什麼變化,最近終於有了一些進步,在德文引擎上尤其明顯。
我們透過一項詳盡的分析,發現到 Yandex 引擎在處理含有標點符號字元 (例如問號、驚嘆號、引號和斜線號等) 及度量衡單位的句子上有進步。 這些改進可能是源自於 MT 設定上的細微調整,而非模型上的改善。 然而,我們在追蹤罕見詞彙時也看到了進步,所以也可能是模型的微調或是更多的資料訓練,使得 Yandex 有所改善。
去年此時,也有數個 MT 引擎展現了我們頗為關注的改善。 因此我們開始思考:這樣的進步是否有時間上的固定模式? 我們今年也會觀察到有如 2021 年的情形嗎? 我們會持續追蹤這些引擎的 MT 效能,並在下個月左右報告我們的發現。
總的來說,人們對 MT 引擎評估越來越感興趣。 時至今日,大多數的人都同意,MT 已是個成熟的技術。 無論是否採用人工干預還是混合作法,人們已經體認到這個技術對幾乎任何翻譯案例而言都很實用。 但該如何妥善地評估、衡量與改善 MT 結果,MT 使用者則仍在求取合適的評估方式。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 3 月
長期關注這個網頁的朋友,一定很熟悉我們對常見 MT 所做的比較評估報告。 每個月,我們都會說明特定語言組合表現最佳的 MT 引擎為何,並追蹤這些引擎的進展。 在 3 月,不同 MT 引擎的效能表現都持平。 這個趨勢已經持續了好一陣子, 正如我們上個月的評論,這可能代表我們需要一個新的 MT 典範。
在我們與大眾分享一般性評估結果的同時,也有越來越多的公司要求我們提供客製化 MT 比較評估。 與一般版本不同的是,這些評估會將公司的具體需求納入考量,來判斷哪些 MT 引擎對他們最為有利。
對於想開始使用 MT 或改善目前 MT 使用方式的公司來說,首要之務就是要找出最適合他們的 MT 引擎。 因此我們在進行客製化評估時,雖然採用的作法跟這個網頁所示的方式雷同,但會根據公司的內容類型跟語言組合要求來提出建議。
客製化 MT 比較評估的提供雖然已有數年之久,但對這類報告的需求卻是有增無減。 我們認為這是因為 MT 在協助企業成功立足數位市場之上,扮演了非常重要的角色。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 2 月
Google 的 MT 引擎在 2022 年 1 月及 2 月有小幅的進步,而我們關注的其他引擎,表現則停滯不前。 這項觀察結果使我們開始思考一些很尖銳的問題: 神經機器翻譯 (NMT) 這個典範是否已經達到頂點? 如果這些引擎無法再有長足的進展,我們是否需要改採新的做法? 畢竟在 NMT 取代統計式 MT 時,我們也觀察到類似的趨勢。
統計式 MT 時代落幕之際,MT 輸出品質幾乎可說沒什麼變化; 此外,不同 MT 引擎的輸出品質也漸趨相同。 現在我們也看到類似的走向。 儘管 NMT 還不會馬上被取代,但如果我們相信指數成長和加速回報理論,再將規則式 MT 為期 30 年和統計式 MT 盛行十數年的壽命納入考量,以 NMT 問世到目前進入第六年來看,或許不久之後就會出現新的典範轉移。

—Lionbridge 創新副總裁 Rafa Moral
2022 年 1 月
在 1 月這段期間,主流機器翻譯 (MT) 引擎的效能表現並未出現大幅改變。
Google 在部分語言和領域上,表現有微幅改善。 其他多數引擎的效能都屬持平。 Microsoft 在過去幾個月有所改良,但其效能在 1 月未見提升。 整體而言,在一般用途的 MT 技術領域上,Google 的翻譯品質持續領先。
在 12 月,我們在追蹤工具中加入了第五個 MT 引擎。 透過監控 Yandex,我們可以更精準地分析俄語的 MT 品質。

—Lionbridge 創新副總裁 Rafa Moral
2021 年 12 月
我們在 12 月時,在機器翻譯追蹤工具的品質比較中加入了新的成員:Yandex MT。
根據我們的測試集,Yandex 截至目前的表現如下:
- 在俄文方面的表現優於 MS Bing,與 Google 相近,但不如 Amazon 和 DeepL。
- 在德文方面的表現與 Amazon 和 MS Bing 相近。
- 在我們追蹤的其他語言組合方面,表現則不如主要的 MT 引擎。
- 在翻譯超過 50 字的長句上表現不錯。
另外我們也觀察到,MS Bing 在 2021 年最後幾個月的輸出改善令人激賞,譯入中文的進步尤其優異。 Amazon 也有不少改進。 邁入新的一年,則由 Google 率先在輸出結果上有所改善, 更明確地說,他們譯入西班牙文、俄文和德文的成績都有進步。 追蹤已達五週的 Yandex 表現曲線則持平,沒有多大變化。

—Lionbridge 創新副總裁 Rafa Moral
2021 年 11 月
Microsoft 自然語言處理 (NLP) 的工程人員顯然抓到了訣竅,經過幾週的實驗,整體表現上下震盪後, Bing 翻譯工具的整體表現在過去幾週有所提升,中文方面更是有長足的進步,使得該 MT 引擎榮登上月表現最佳的寶座。 Bing 翻譯工具在大部分領域中的表現已經趕上部分競爭對手,甚至有超越這些對手表現的情形。 Bing 翻譯工具仍舊是訓練潛力數一數二優秀的引擎,而功能上的進步,也使得它會是您為內容建置專用客製化模型時不錯的選擇。

—Lionbridge 語言卓越能力團隊副總裁 Jordi Macias
2021 年 10 月
10 月,Amazon 的機器學習 (MT) 引擎憑藉著之前一個多月來的成果不斷改善,持續與時俱進,締造了相當優秀的成果。根據我們觀察,這是 Amazon 過去幾個月內推出的第二波持續改善。
若您不太清楚 Amazon 過去的成績,在過去幾個月內,Amazon 的機器學習引擎在下面幾個領域中不斷改進:
- 翻譯的風格比以往更自然貼切
- 採用全新方式處理度量衡單位
- 目前會固定顯示英制與公制的度量衡數值
- 英制度量衡現在會顯示在公制度量衡的前面
- 現在能分別正確翻譯兩種度量衡的數值
- 目前會將 Euro 譯為各語言的「歐元」,不再保留貨幣符號 €

—Lionbridge 語言卓越能力團隊副總裁 Jordi Macias
2021 年 9 月
Amazon 的機器翻譯 (MT) 引擎在 9 月的表現可謂可圈可點。首先,Amazon 改善了他們德文與俄文的 MT 輸出品質;其次,他們在西班牙文與中文這個語言組合上的表現也有進步。這是過去幾個月內我們觀察到他們的第二波改善。
Amazon MT 引擎還有以下一些改變:
- 推出比以往更口語化的風格
- 改變了度量衡單位的處理作法
- 目前會固定同時顯示英制與公制的度量衡數值
- 英制度量衡現在會顯示在公制度量衡的前面
- 現在能分別正確地翻譯兩種度量衡的數值
- 目前會以「Euro」(歐元) 取代貨幣符號 €

—Lionbridge MT 專員 Yolanda Martin
2021 年 8 月
所有科技企業龍頭都已開發自己的 MT 引擎,其中包括 Microsoft、Google、Amazon、Facebook 以及最新加入這個行列的 Apple。而美國以外市場中的許多其他主要企業,也紛紛投入這個領域爭取領先。這些一流科技企業顯然都相信,MT 和自然語言處理 (NLP) 技術,對現今連結日趨緊密的全球化世界來說,是不可或缺的工具。
歡迎跟著 Lionbridge 一起,密切關注這個領域的競爭局勢。我們會根據公司的特殊需求、想要使用的語言組合與內容類型等因素,進行周密的全盤考量,找出最合適的 MT 引擎選擇。
隨著眾多一流科技企業投入心力開發 MT/NLP,相信這場競賽將更加激烈。隨著向來以注重細節和品質聞名的 Apple 加入這場戰局,也無疑會促使其他企業卯足全力求取進步。

—Lionbridge 創新副總裁 Rafa Moral
認識我們的機器翻譯專家



